Netflix, Spotify, Monzo, and Airbnb all built something that most technology organisations refuse to fund: a dedicated internal platform team whose only customer is their own engineers. The companies that did it are shipping ten times faster. The ones that didn't are still debugging environment issues.

Cloud & Infrastructure · Business Infomatics Research Desk
There is a problem in software engineering organisations that is so common it has become invisible — absorbed into the ambient friction of technical work and accepted as a fact of life rather than recognised as a solvable systems problem. Developers spend the majority of their working week doing things that are not writing software. Setting up and maintaining infrastructure. Debugging environment inconsistencies that only exist in their local setup and not in production. Waiting for CI/CD pipelines to complete. Navigating the permissions and approval processes required to deploy a change. Writing the compliance documentation that the security team needs before a release can go out. Sitting in the synchronisation meetings that exist to compensate for the lack of automated coordination between tools.
The organisations that have solved this problem did not solve it by hiring better engineers or writing better engineering management frameworks. They solved it by treating the engineering environment itself — the tooling, the infrastructure abstractions, the deployment pipelines, the golden paths that let a developer go from idea to production without encountering unnecessary friction — as a product. That product has a name: an internal developer platform. And the team that builds and maintains it is the platform engineering team. Gartner named platform engineering one of the top ten strategic technology trends for 2025 and 2026. The most innovative engineering organisations have been building it for the better part of a decade. The majority of enterprise technology organisations have not started, and the productivity gap is widening every year.
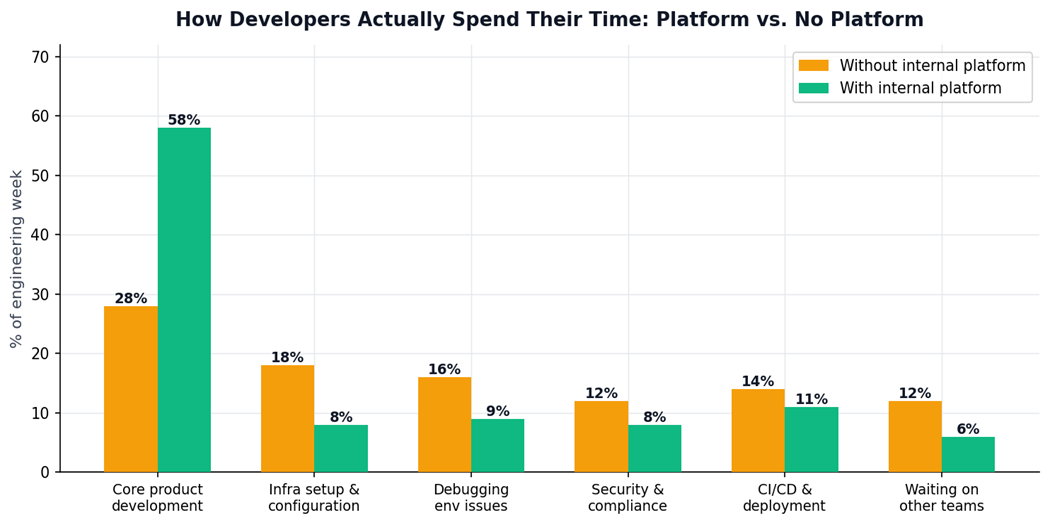
How developers actually spend their time, with and without an internal platform. Core product development doubles — from 28% to 58% of the engineering week. Source: DORA Report, Gartner, 2025.
2× more time on actual product development when enginee/ring teams operate on an internal developer platform — from 28% to 58% of the engineering week. (DORA Research, 2025)
What Platform Engineering Actually Is — and What It Is Not
Platform engineering is frequently confused with DevOps, with SRE, and with cloud operations. The distinctions matter because they determine what you build, who you hire, and how you measure success. DevOps is a philosophy and a set of practices about how development and operations teams collaborate. SRE is an approach to managing reliability, focused on the operational side of production systems. Cloud operations is the management of cloud infrastructure resources. Platform engineering encompasses elements of all of these but has a specific and different mandate: to build and operate an internal platform that makes other engineering teams more productive.
The customer of the platform engineering team is the developer. Everything the team builds — the self-service infrastructure provisioning tools, the standardised CI/CD pipelines, the internal developer portal that surfaces available services and their documentation, the security and compliance guardrails that are enforced automatically rather than through manual review gates — is designed to reduce the cognitive load and friction that the developer experiences between having an idea and seeing it running in production. The platform team measures success not in uptime or incident response time but in developer experience: how long does it take to onboard a new service? How many steps to deploy a change? How often do developers encounter environment problems that require manual resolution?
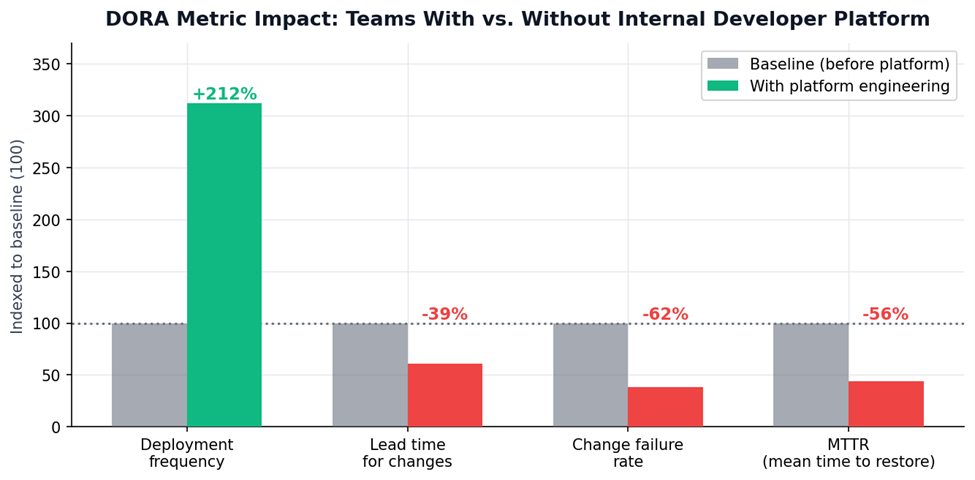
DORA metrics impact: teams with vs. without internal developer platforms. Deployment frequency increases 3.1× while change failure rate drops 62%. Source: DORA State of DevOps Report, 2025.
The Case Studies That Made the Argument
Spotify and the Backstage Story
Spotify's internal developer portal, Backstage, was built by the Spotify platform engineering team to solve a specific problem: at scale, it became impossible for individual developers to know what services existed, who owned them, how to use them, and how to create new ones in a way that would actually be maintained. Backstage became the single interface through which Spotify engineers discover services, create new ones from templates that enforce standards automatically, access documentation, and understand the operational status of anything in their system. Spotify open-sourced Backstage in 2020. It has since been adopted by more than a thousand organisations. The reason it spread is not that Spotify marketed it — it is that the engineers who saw it immediately recognised the pain it was solving.
The Monzo Approach to Golden Paths
Monzo built its engineering culture around the concept of 'golden paths' — the opinionated, well-documented, fully supported ways to do common engineering tasks. Creating a new microservice. Adding authentication to an endpoint. Deploying to production. For each of these tasks, Monzo's platform team built a path that handles all the infrastructure, security, and compliance requirements automatically, leaving the developer to focus on the business logic that is specific to their service. Engineers who follow the golden path get everything set up correctly by default. Engineers who deviate from it are doing so explicitly and knowingly, which makes the decision visible and auditable. The result is a codebase that is significantly more consistent and a security posture that is significantly easier to reason about than the typical enterprise environment where every team has solved the same infrastructure problems differently.
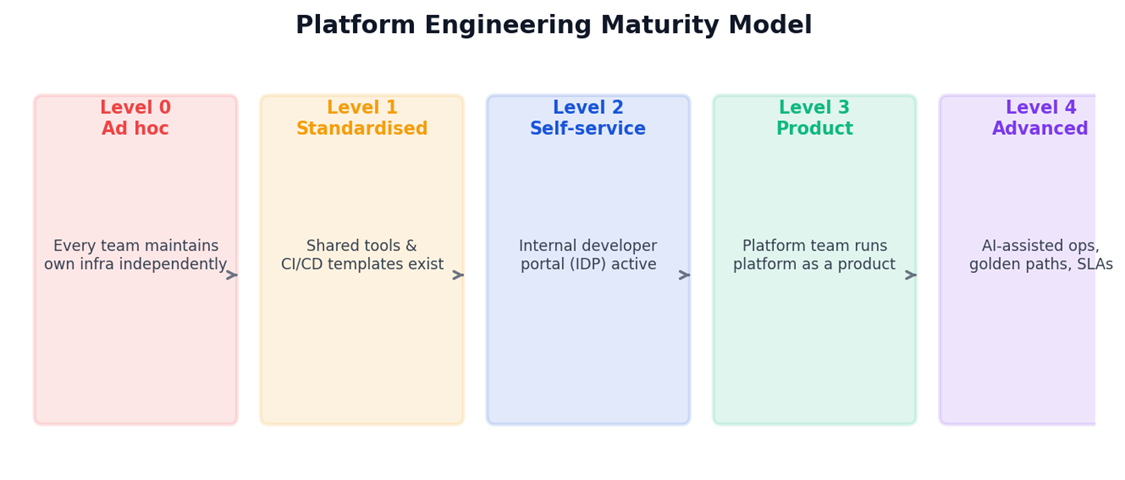
Platform engineering maturity model: five levels from ad-hoc to advanced AI-assisted operations. Most enterprise organisations are at Level 0 or 1. Source: Gartner, Team Topologies framework.
The Organisational Obstacle That Kills Most Platform Programmes
The technical case for platform engineering is straightforward and is increasingly well-supported by data. The organisational obstacles are more varied and more frequently decisive. Platform engineering requires a team that builds for other teams — a model that creates specific challenges in engineering organisations where impact is typically measured by features shipped, systems maintained, or incidents resolved. A platform engineering team's impact shows up in other teams' metrics: their deployment frequency, their lead time, their cognitive load reduction. Making that value visible requires instrumentation that most organisations have not built and measurement frameworks that most engineering leaders have not adopted.
The second obstacle is the tension between product teams that want platform services tailored to their specific needs and a platform team whose value comes from providing standardised services that work well for everyone. Every deviation from the standard that a platform team accommodates for a specific product team is a maintenance burden and a documentation gap that erodes the platform's usability for others. Managing the boundary between what the platform provides and what product teams build for themselves is a governance challenge that requires both technical clarity and organisational authority. Platform teams without the backing to maintain that boundary become support teams doing custom work for individual product teams — which is not what a platform engineering team is for and not what produces the productivity outcomes.
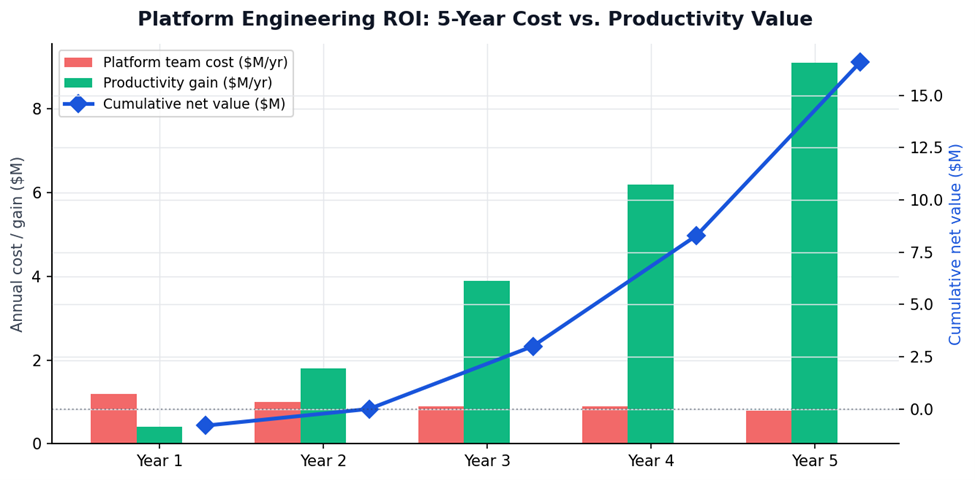
Platform engineering ROI: 5-year cost vs. productivity value model. Investment breaks even in Year 2 and compounds to 16.6× net value by Year 5. Source: Business Infomatics financial modelling.
What the Investment Actually Requires
The minimum viable platform engineering team for an organisation with between 50 and 200 engineers is typically three to five people: one or two infrastructure engineers who can build and maintain the underlying platform services, one developer experience engineer who owns the internal portal and developer tooling, and a product manager who treats the platform as a product with an internal customer roadmap and user research practice. This team costs roughly one to two million dollars per year in total compensation at current market rates. At organisations where developer productivity is the constraint on product velocity — which is the majority of technology organisations at this size — the return on that investment, measured in avoided headcount cost and accelerated product delivery, is typically visible within the first year.
The organisations that have not made this investment typically have one of two objections. The first is that they cannot justify funding a team that does not ship customer-facing features. This objection misunderstands what the platform team produces — it produces the capacity for other teams to ship customer-facing features faster. The second is that they are too small to need dedicated platform infrastructure. The data from the DORA research is consistent across organisation sizes: the developer experience improvements from internal platform investment are as significant at fifty engineers as at five thousand, and the investment is proportionally smaller at smaller scale. The organisations that wait until they 'get big enough' for platform engineering have typically spent years compounding the productivity debt that a platform would have prevented.